![rand[om]](/img/bike_m.png)
Building a remote SQLite explorer
Table of contents
One of the main pain points of using SQLite in production deployments or VMs is managing the database. There are lots of database GUIs, but only work with local SQLite databases. Managing an SQLite database remotely requires:
- Adding a new service to the deployment (like Adminer, sqlite-web or postlite)
- Giving the new service permissions to access the volume with the database
- Exposing a port to access the service The alternative is usually SSH’ing to the remote VM and use the sqlite3 CLI to manage or explore the database.
With this in mind, I decided to build a remote SQLite management GUI that does not require running any service in the remote VM and only needs an SSH connection between you and the remote machine.
Turning a database into an API
To access the remote database, we need some communication format between the app’s code and the database data. Luckily for us, the sqlite3 CLI has a -json flag that will turn the output into JSON. We can use that to send CLI commands over the SSH connection and read the JSON output as the response. One thing to note is that some pre-installed sqlite3 CLIs have not been compiled with the -json flag enabled. You may need to install/scp/compile another sqlite3 binary in the remote to do this.
ssh $SSH_USER@$SSH_HOST "sqlite3 -json chinook.sqlite3 'select * from Artist limit 10'"
The output looks like:
[
{ "ArtistId": 1, "Name": "AC/DC" },
{ "ArtistId": 2, "Name": "Accept" },
{ "ArtistId": 3, "Name": "Aerosmith" },
{ "ArtistId": 4, "Name": "Alanis Morissette" },
{ "ArtistId": 5, "Name": "Alice In Chains" },
{ "ArtistId": 6, "Name": "Antônio Carlos Jobim" },
{ "ArtistId": 7, "Name": "Apocalyptica" },
{ "ArtistId": 8, "Name": "Audioslave" },
{ "ArtistId": 9, "Name": "BackBeat" },
{ "ArtistId": 10, "Name": "Billy Cobham" }
]
(Note: I’m using the chinook database as an example)
Multiplexing connections
The problem with sending commands over SSH is that it requires creating a new SSH connection/session for each command. To avoid this, we can use connection multiplexing. We can tell SSH to keep the connection open as a socket and reuse that if another connection is made before some time threshold. With this, we removed the overhead of creating new TCP connections and negotiating the secure connection for each query.
ssh -o ControlPersist=1m -o ControlMaster=auto -o ControlPath=~/.ssh/persistent-socket $SSH_USER@$SSH_HOST "sqlite3 -json chinook.sqlite3 'select * from Artist limit 10'"
ControlPersist=1m will make the connection persist for 1 minute after the last command/connection. You can learn more about SSH multiplexing here.
I did some tests from my laptop in Spain, querying a database (different than chinook) in a server in Germany.
A simple query (select * from sqlite_master) reported the following timings:
real 0m0.147s
user 0m0.032s
sys 0m0.018s
For a query which selects more data like select * from user limit 100, the timings are:
real 0m0.160s
user 0m0.020s
sys 0m0.011s
I think this is fast enough to “build an API” on top of sending CLI commands over a multiplexed SSH connection.
Extra benchmarks
I also queried a chinook database running in a VM in the US to have more geo-latency. When querying 10 “Artists”:
ssh -o ControlPersist=1m -o ControlMaster=auto -o ControlPath=~/.ssh/persistent-socket $SSH_USER@$SSH_HOST "sqlite3 -json chinook.sqlite3 'select * from Artist limit 10'"
The timings are:
real 0m0.317s
user 0m0.011s
sys 0m0.016s
For 200 “Artists”:
real 0m0.458s
user 0m0.010s
sys 0m0.015s
Complex queries
One problem with this approach is sending complex SQL queries. We don’t want to send huge commands with weird quote escaping. But we can just pass the query as input to the command. From the command line, we can store the query in a text file:
ssh my_host "sqlite3 -json chinook.sqlite3" < query.txt
Or as a Python string using subprocess.run:
import subprocess
query = """
SELECT * FROM users LIMIT 10;
"""
p = subprocess.run([...], input=query)
litexplore
This is how litexplore was born. It’s a (very basic for now) web UI on top of the techniques mentioned above.
When you start the server, you’re prompted with a form, asking for the SSH remote (as defined in your ~/.ssh/config), the path of the SQLite database in the remote and (optionally) a path to the sqlite3 CLI.
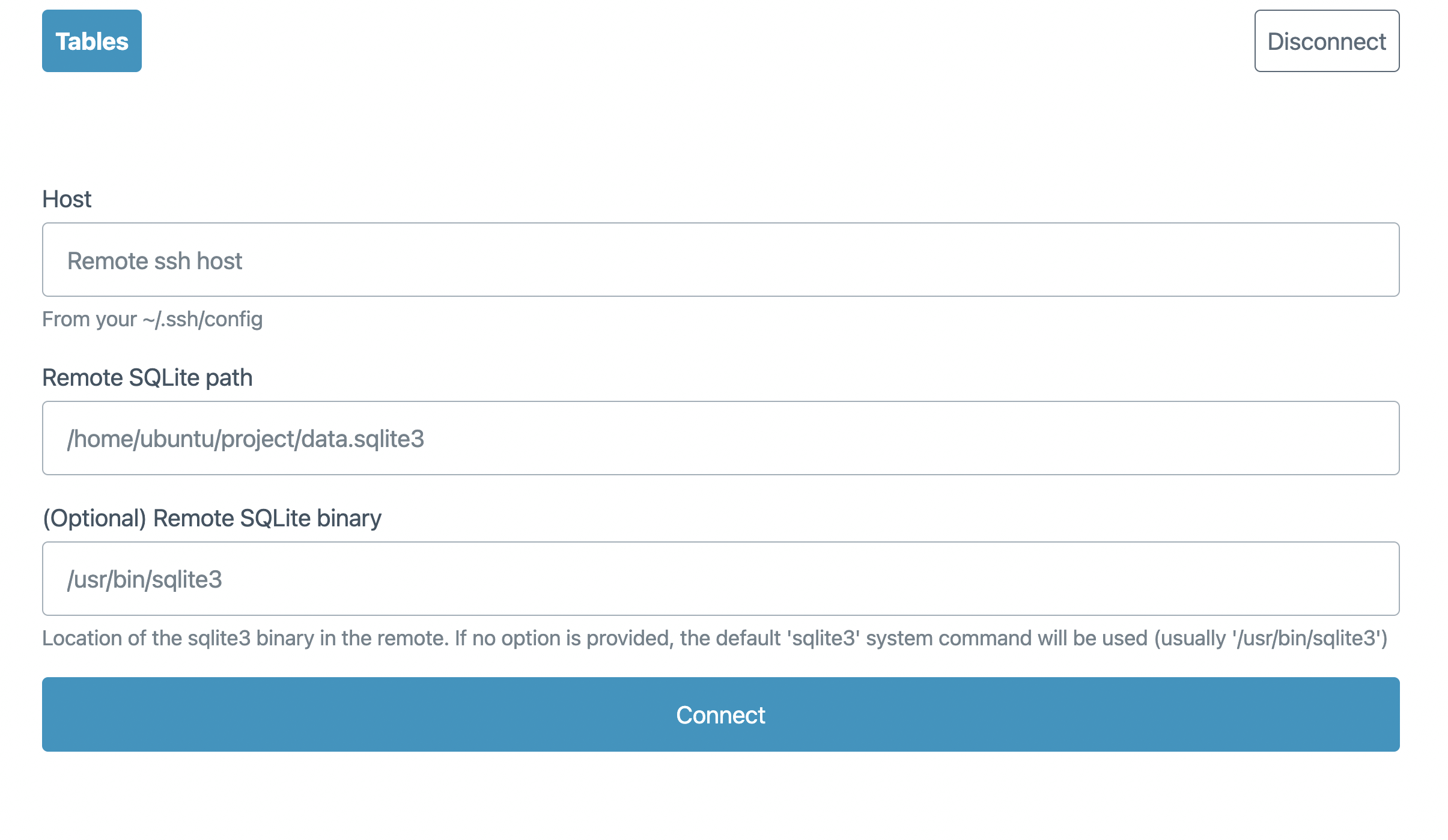
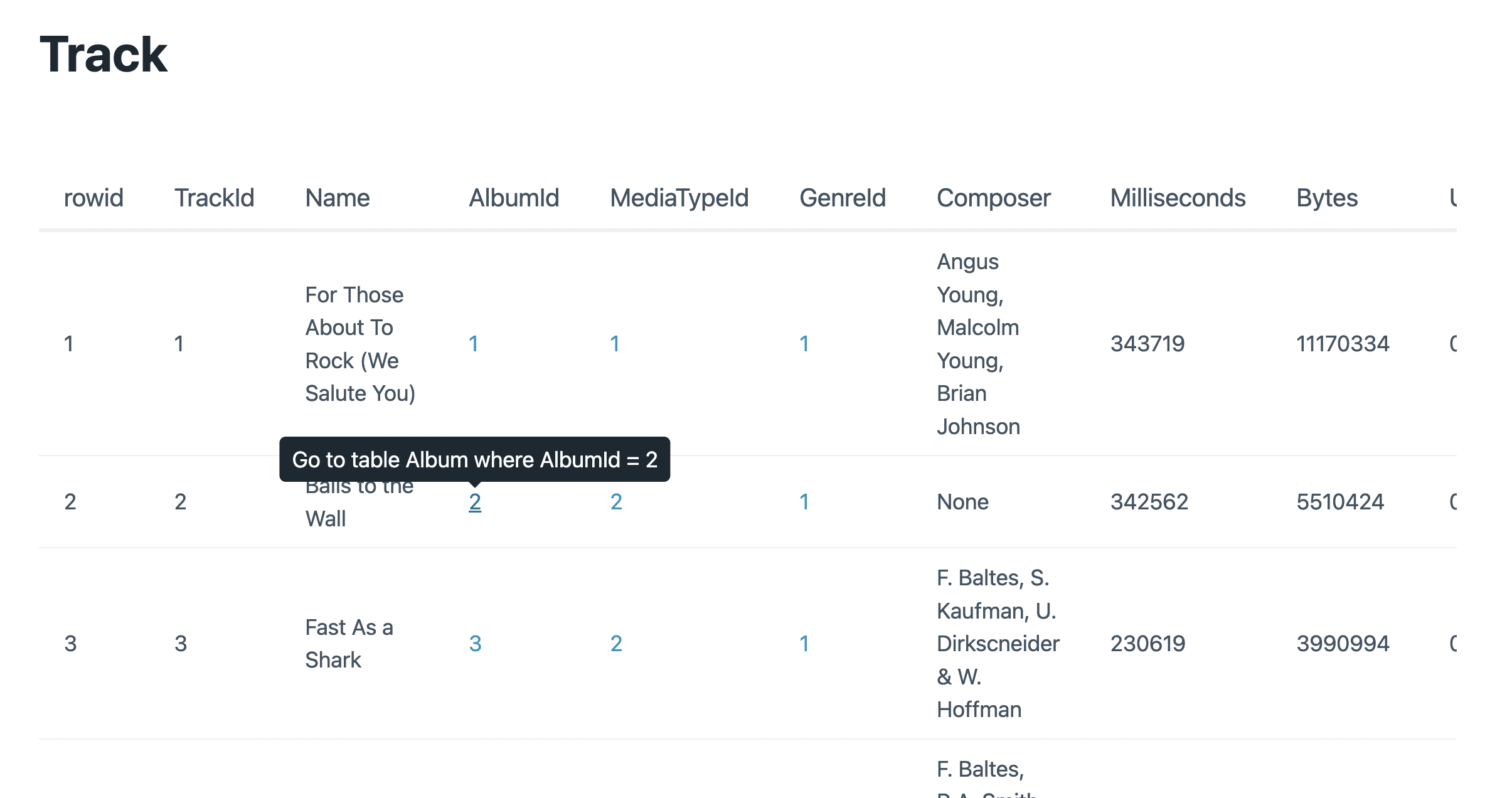
The app will make sure that the remote sqlite3 CLI has the -json option available and proceed to show a basic UI to explore the database.

Table views will link to foreign keys in each entry.
The app still has some limitations, but has many features in the roadmap. You can follow the development and provide feedback on GitHub.
The main reason why I’ve started building litexplore is that you just need an SSH connection. No extra apps, containers or open ports are needed in the remote!
Query parameters, SQL injection and security
The main purpose of litexplore is navigating a remote database without having to use the terminal/CLI. By default, all the commands open the remote database in read-only mode, so a potential malicious query can’t modify a database.
sqlite3 -json file://test.sqlite3?mode=ro
The sqlite3 CLI can also pass parameters to queries by using a temporary table. We can use this feature by using the .parameter (or the .param alias) command. We can then send queries like this:
.param init
.param set :limit "50"
.param set :offset "0"
select _rowid_ as rowid, * from Track limit :limit offset :offset
This ensures that queries are properly parametrized instead of having to manually escape the parameters when constructing the string.
Closing words
The development of litexplore is just starting, feel free to give any feedback on the GitHub repo. I’m also considering turning it into an (Electron) installable app. Or creating an SQLite VFS to query remote databases through SSH without having to run a web app.