![rand[om]](/img/bike_m.png)
Language identification with fastText
Table of contents
When dealing with a multilingual dataset doing language identification is a very important part of the analysis process, here I’ll show a way to do a fast ⚡️ and reliable ✨ language identification with fasttext.
<TL;DR>
wget https://dl.fbaipublicfiles.com/fasttext/supervised-models/lid.176.bin
import fasttext
lid_model = fasttext.load_model('lid.176.bin')
def detector(text):
# return empty string if there is no tweet
if text.isspace():
return ""
else:
# get first item of the prediction tuple, then split by "__label__" and return only language code
return lid_model.predict(text)[0][0].split("__label__")[1]
df['language'] = df['Tweet'].apply(detector)
</TL;DR>
First fo all we need to download a dataset to play with. We’ll use the kaggle CLI tool. Run the following command after installing it or download the dataset directly from kaggle.
kaggle datasets download -d rtatman/the-umass-global-english-on-twitter-dataset
import pandas as pd
df = pd.read_csv('the-umass-global-english-on-twitter-dataset.zip', sep='\t')
df.head()
| Tweet ID | Country | Date | Tweet | Definitely English | Ambiguous | Definitely Not English | Code-Switched | Ambiguous due to Named Entities | Automatically Generated Tweets | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 434215992731136000 | TR | 2014-02-14 | Bugün bulusmami lazimdiii | 0 | 0 | 1 | 0 | 0 | 0 |
| 1 | 285903159434563584 | TR | 2013-01-01 | Volkan konak adami tribe sokar yemin ederim :D | 0 | 0 | 1 | 0 | 0 | 0 |
| 2 | 285948076496142336 | NL | 2013-01-01 | Bed | 1 | 0 | 0 | 0 | 0 | 0 |
| 3 | 285965965118824448 | US | 2013-01-01 | I felt my first flash of violence at some fool... | 1 | 0 | 0 | 0 | 0 | 0 |
| 4 | 286057979831275520 | US | 2013-01-01 | Ladies drink and get in free till 10:30 | 1 | 0 | 0 | 0 | 0 | 0 |
print(f"""There are: {df.Tweet.shape[0]} tweets.
First 10 tweets:
{df['Tweet'].head(10)}""")
There are: 10502 tweets.
First 10 tweets:
0 Bugün bulusmami lazimdiii
1 Volkan konak adami tribe sokar yemin ederim :D
2 Bed
3 I felt my first flash of violence at some fool...
4 Ladies drink and get in free till 10:30
5 @Melanynijholtxo ahhahahahah dm!
6 Fuck
7 Watching #Miranda On bbc1!!! @mermhart u r HIL...
8 @StizZsti fino
9 Shopping! (@ Kohl's) http://t.co/I8ZkQHT9
Name: Tweet, dtype: object
Looking at the first 10 tweets we can already see there are multiple languages been used. Let’s now use fasttext to classify them. You need to download the language identification model to use it, run the following shell command if you need to do so.
wget https://dl.fbaipublicfiles.com/fasttext/supervised-models/lid.176.bin
Alternatively, you can use a slightly less accurate but a lot smaller model:
wget https://dl.fbaipublicfiles.com/fasttext/supervised-models/lid.176.ftz
And now we can use it.
import fasttext
lid_model = fasttext.load_model('lid.176.bin')
Create a list in which each item is a tweet.
corpus = df['Tweet'].to_list()
Predict the language of the first tweet.
tweet = corpus[0]
prediction = lid_model.predict(corpus[0])
print(f"Text:\n \t {tweet} \n \n Prediction:\n \t {prediction}")
Text:
Bugün bulusmami lazimdiii
Prediction:
(('__label__tr',), array([0.77383512]))
The output of the prediction is a tuple of language label and prediction confidence. Language label is a string with “__label__” followed by ISO 639 code of the language. You can check the language codes here and the languages supported by fasttext at the end of their blog post.
Let’s try with a different one.
print(f"Text:\n \t {corpus[4]} \n \n Prediction:\n \t {lid_model.predict(corpus[4])}")
Text:
Ladies drink and get in free till 10:30
Prediction:
(('__label__en',), array([0.65553886]))
Now we can create a new column with the language of each tweet.
def detector(text):
# return empty string if there is no tweet
if text.isspace():
return ""
else:
# get first item of the prediction tuple, then split by "__label__" and return only language code
return lid_model.predict(text)[0][0].split("__label__")[1]
%%time
df['language'] = df['Tweet'].apply(detector)
CPU times: user 258 ms, sys: 4.17 ms, total: 262 ms
Wall time: 266 ms
I added the %%time IPython command to show one of the main reasons to use fasttext, the speed ⚡️. In 250ms I processed 10502 tweets working on a 2016 laptop with a dual-core 2 GHz Intel Core i5 processor.
The speed of fastText can also be compared with langid.py in this table from their blog.
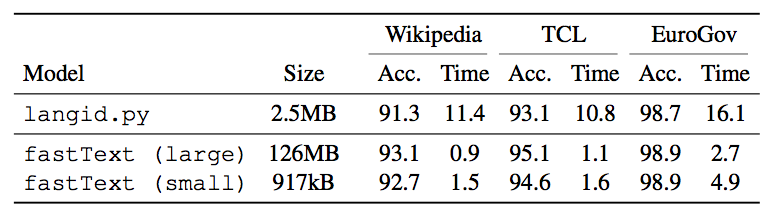
Finally, if we wanted to work only with a subset of the languages and convert the rest to “unk” (and maybe use a multilingual model when working with them), we can use the following.
# keep the 4 top languages according to the current predictions
languanges_keep = df.language.value_counts().index[:4].to_list()
# create a custom list
languanges_keep = ["en", "es", "pt", "ja"]
df.loc[df.language.apply(lambda x: x not in languanges_keep), 'language'] = "unk"
df.language.value_counts()
en 5735
unk 2247
es 1139
pt 876
ja 505
Name: language, dtype: int64
And from here we can keep working with our text data!