![rand[om]](/img/bike_m.png)
The best code is easy code
Table of contents
The best code is the one that is easy to understand.
The problem
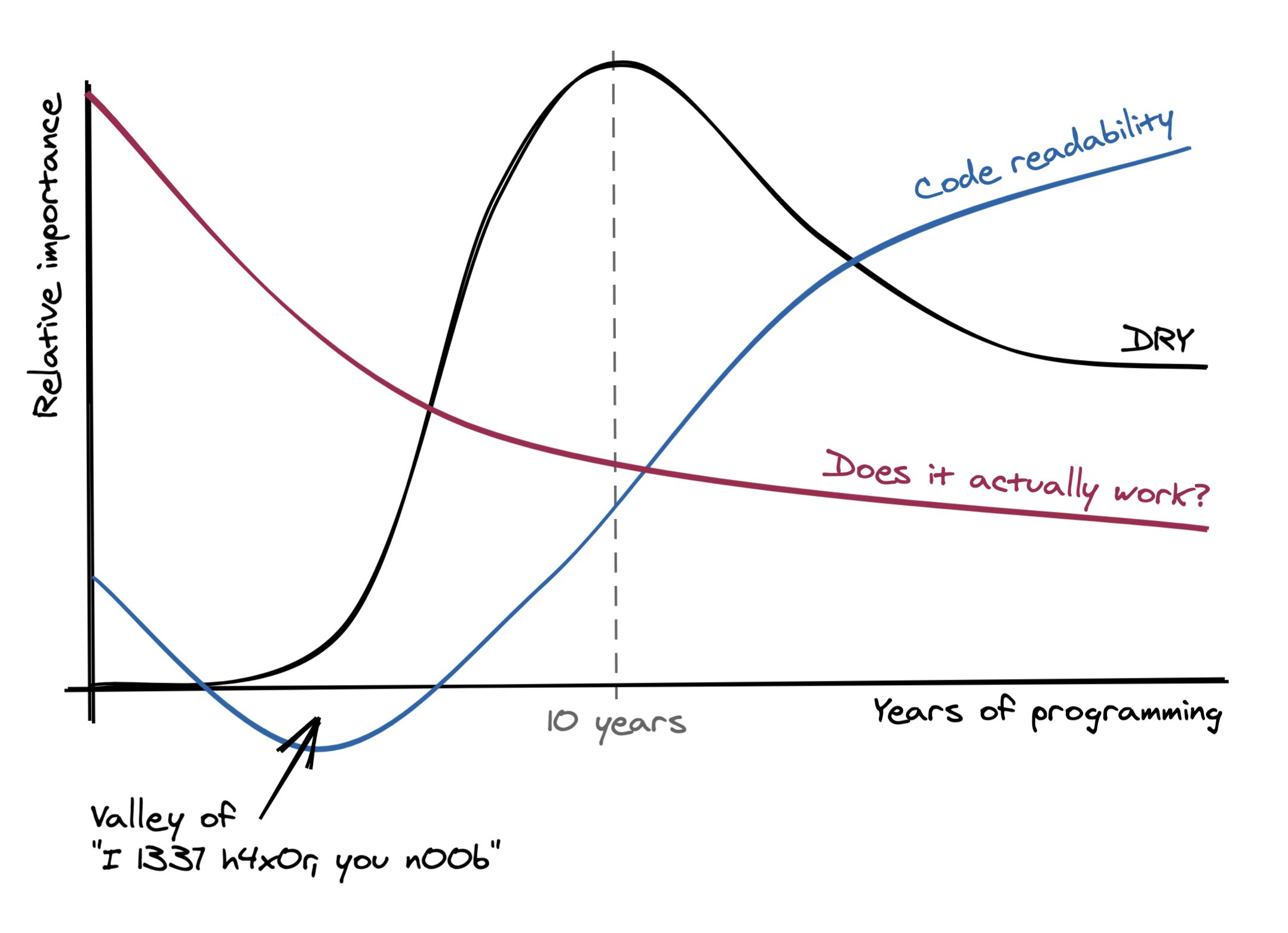
People don’t focus on code readability. Readability is like writing documentation. It takes extra time, more key presses, and you need to stick to it to make it work in the long term. However, sometimes people write code like this:
settings = {"foo": 1, "bar": 2, "baz": 3}
results = [parse_document(settings, r)["somekey"].get("foobar", "") for r in get_documents()]
This code is understandable, but I need to guess:
- I suppose
parse_document()is returning some kind of dictionary - There’s another indexing operation. The dictionary is probably nested.
- What is
r? - Is
parse_document()mutatingsettings? Cansettingshave other keys?
When you find a situation like this, the solution is usually going inside the functions and reading the code, which may be tedious. Yes, maybe you are avoiding creating a couple of variables, but at what cost?
The issue with code like that is that it becomes impossible to maintain or modify.
Why does code like that exist?
Context!. That’s what you don’t have in your mind. The person writing that code probably had a lot of context in mind and could easily reason about it, but now you don’t. At some point, the code was obvious (either for your past self, or worse, someone else) because you knew exactly about everything happening at that point of the execution.
The solution
I think the easiest way to start fixing that is:
- More intermediate variables! (No, that probably won’t be the bottleneck in your software in terms of performance)
- Longer variable names.
result,element,item, etc. are usually not self-explanatory enough. - Make it extremely obvious.
I find that last point the most difficult one. Making the code extremely obvious may feel like you’re back to when you started programming, giving a name to absolutely everything. I think that’s good.
For the example above, I would imagine something like:
@dataclass
class DocumentProcessingSettings:
foo: int = 1
bar: int = 2
baz: int = 3
raw_document_list = get_documents()
processed_documents = [parse_single_document(DocumentProcessingSettings , doc) for doc in raw_document_list]
filtered_processed_documents_intermediate = [doc["somekey"] for doc in processed_documents]
filtered_processed_documents = [doc.get("foobar", "") for doc in filtered_processed_documents_intermediate]
Or:
@dataclass
class DocumentProcessingSettings:
...
filtered_processed_documents = []
for document in get_documents():
parsed_document = parse_single_document(DocumentProcessingSettings , document)
filtered_document = parsed_document["somekey"]
processed_document = filtered_document.get("foobar", "")
filtered_processed_documents.append(processed_document)
Some advantages that we have now:
settingsis an actual object (class, struct or whatever) with a self-explanatory name. Now we know which keys it can have, and we’ll get an error if the object does not have all the needed keys.- The code is easier to debug, either with a debugger or
print(). We have separated all the processing steps. - The code is easier to understand.
- If something breaks, it’s faster to point out the issue. In the initial example we may not know what’s failing, there are many things going on in a single line.
(The graph at the beginning also mentions “DRY”. I’ll leave that for another post.)
Conclusion
If someone else is randomly dropped in the line you’re writing, how long would it take to understand what’s going on? Could they explain it in less than 5 minutes? Maybe we need to get back to the “newbie” mindset. Make things obvious.